Introduction
In Astrogator, an Optimal Finite Maneuver is a finite maneuver designed so that a certain mission objective, such as the time of flight, propellant consumption etc., is minimized during the maneuver. Optimization of an objective or a cost function is typically achieved by appropriately selecting the thrust attitude program, the initial/final vehicle orbit states, and possibly also the maneuver duration. Astrogator computes these quantities by utilizing the well-established mathematical framework from Optimal Control Theory and implementing state-of-the-art numerical algorithms from Computational Trajectory Optimization. Optimal Control Theory solves problems of the following type: find the state-control function pair 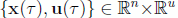 and epoch(s) T0 and/or Tf such that the cost functional:
and epoch(s) T0 and/or Tf such that the cost functional:
(1)
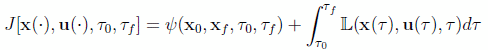
is minimized subject to the differential-algebraic system of equations:
(2)
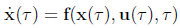
(3)
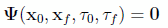
and optionally, also a system of path constraints:
(4)
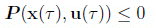
where 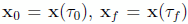 . We assume that the problem functions
. We assume that the problem functions 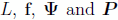 are continuously differentiable to their arguments and their gradients are Lipschitz-continuous over the domain of interest. For an Astrogator satellite:
are continuously differentiable to their arguments and their gradients are Lipschitz-continuous over the domain of interest. For an Astrogator satellite:
- The state x(T ) is its position, velocity and mass,
- The control functions u(T) are the thrust attitude direction cosines or spherical angles in a specified reference frame,
- The dynamical equations are those modeled by the available propagator force models, such as Earth Point Mass, Earth J2, Heliocentric etc.
In its current implementation, the Astrogator Optimal Finite Maneuver does not support the explicit setting of path constraints.
Direct Transcription Methods
A standard technique for solving an Optimal Control or Trajectory Optimization problem as posed by Eqs. (1) - (4) is to convert or transcribe it into a numerical optimization problem involving a finite number of parameters and then solve this parameter optimization problem using a nonlinear programming (NLP) library. In Astrogator, pseudospectral methods - in particular, the Legendre Pseudospectral Method (LPM) and Radau Pseudospectral Method (RPM) - are used to complete the transcription. In the computational optimal control literature, these are examples of direct methods, as opposed to the indirect method which is based on Pontryagin's Minimum Principle, and numerically less robust [1, 2]. A brief description of the LPM and RPM follows. For more details, please see Gong et al. [3] (LPM), Garg et al. [4] (RPM) and the references therein.
The Legendre Pseudospectral Discretization
In the Legendre Pseudospectral Method implemented in Astrogator, the states and the controls are assumed to lie in a space of Lagrange interpolating polynomials, i.e. they are expressed as a series expansion of Lagrange basis functions. It is the coefficients of these expansions that are finally solved for by a numerical optimizer. In particular, let 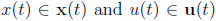 . Also, let
. Also, let 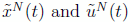 be Nth-order polynomial approximations of x(t) and u(t), based on Lagrange interpolation at the Legendre-Gauss-Lobatto (LGL) quadrature nodes, i.e.
be Nth-order polynomial approximations of x(t) and u(t), based on Lagrange interpolation at the Legendre-Gauss-Lobatto (LGL) quadrature nodes, i.e.
(5)
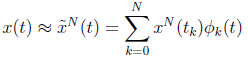
(6)
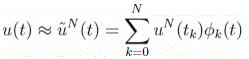
and 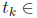 [–1; 1], the LGL nodes, defined as:
[–1; 1], the LGL nodes, defined as:
(7)
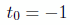
(8)
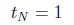
(9)
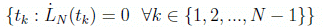
where 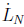 is the derivative of the Legendre polynomial of degree N. Note that in preparation for using the Legendre pseudospectral method, the actual, physical time
is the derivative of the Legendre polynomial of degree N. Note that in preparation for using the Legendre pseudospectral method, the actual, physical time 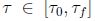 for a certain maneuver segment is internally converted into the computational interval [–1, 1] using the affine transformation:
for a certain maneuver segment is internally converted into the computational interval [–1, 1] using the affine transformation:
(10)
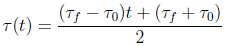
The Lagrange interpolating polynomial of degree N is:
(11)
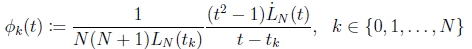
and possesses the property:
(12)
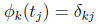
with 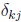 being the Dirac Delta Function. To enforce Eq.(2) at the LGL nodes, Eq.(4) is differentiated and evaluated at the node points, resulting in:
being the Dirac Delta Function. To enforce Eq.(2) at the LGL nodes, Eq.(4) is differentiated and evaluated at the node points, resulting in:
(13)
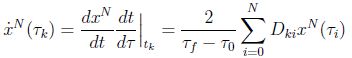
where 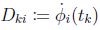 are the elements of the (N + 1)X(N + 1) differentiation matrix DLGL, which you can evaluate as:
are the elements of the (N + 1)X(N + 1) differentiation matrix DLGL, which you can evaluate as:
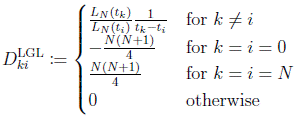
Thus combining approximations (4) and (6) with Eq. (13), the state dynamics described by Eq. (2) can be discretized into the nonlinear set of equations:
(14)
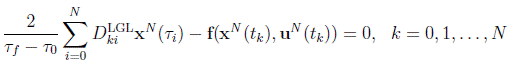
The cost functional of Eq.(1) can be approximated by the Gauss-Lobatto quadrature rule:
(15)
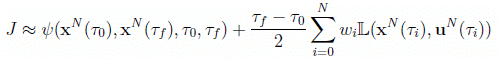
where the LGL weights can be computed from the expression:
(16)
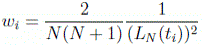
The event constraints Eq.(3) and any path constraints, if present (Eq.(4)), must now also be expressed by the LGL nodal values of the states and controls:
(17)
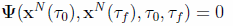
(18)
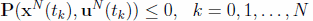
Collecting the nodal values of the states and the controls and the initial/final time into a single decision variable vector:
(19)
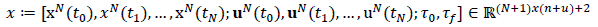
the original dynamic optimization problem posed through Eqs. (1 - 4) can be transcribed into a static optimization problem with cost function given by Eq. (15 ), equality constraints Eq. (14 ) and Eq. (17 ), and if applicable, inequality constraints Eq. (18). In compact notation, the following problem results after discretization:
(20)
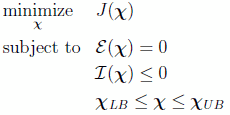
You can solve this problem by a numerical optimization package with user-supplied initial guesses for the decision variables, i.e., the nodal values of the states, controls and initial/final values of the maneuver interval.
The Radau Pseudospectral Discretization
In RPM, a distinction is made between collocation nodes (LGR nodes), points at which the dynamics (Eq. (2)) are enforced, and state support nodes, points at which the states are approximated (at intermediate nodes, the states are evaluated by interpolation). The number of state-support nodes is one more than the number of LGR nodes. The LGR nodes tk 2 [1; 1), where, as in the LGL discretization, physical time is transformed through Eq. (10). The LGR nodes may be computed through:
(21)
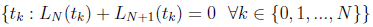
The states are approximated over 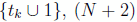 nodes, and the controls over
nodes, and the controls over 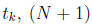 nodes:
nodes:
(22)
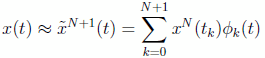
(23)
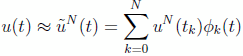
where the symbols are defined in the previous subsection. Following a reasoning like the LGL discretization case, you can see that the LGR differentiation matrix is now non-square, of dimension (N+1) X (N+2), since collocation is not enforced at t = 1. The differential equation constraints in this case reduce to the following set of non-linear equations:
(24)
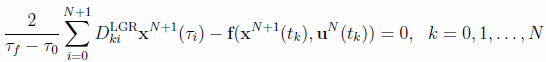
where the LGR differentiation matrix DLGR may be computed from the barycentric formula. The cost functional is now evaluated as in Eq. (15) through a Gauss-Radau quadrature scheme, but with weights given by:
(25)
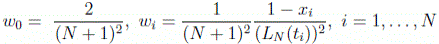
Accounting for event and path constraints of the type Eqs. (17, 18), the parameter optimization problem from LGR discretization assumes the form of Eq. (20). The decision variables are the state values at the state support nodes, the controls at the LGR nodes, and more parameters, such as terminal times:
(26)
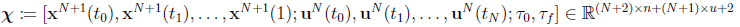
- [1] Bruce Conway, ed., Spacecraft Trajectory Optimization. Cambridge University Press, Cambridge, England, U.K., 2010., Chaps. 2–3.
- [2] John T. Betts., Practical Methods for Optimal Control and Estimation Using Nonlinear Programming. Society for Industrial & Applied Mathematics; 2nd edition., 2009., Chaps. 1–3.
- [3] Qi Gong, Fariba Fahroo and I. Michael Ross, Spectral Algorithm for Pseudospectral Methods in Optimal Control, Journal of Guidance, Control, and Dynamics, Vol. 31, No. 3 (2008), pp. 460-471.
- [4] Divya Garg, Michael Patterson, William W.Hager, Anil V.Rao, David A.Benson, and Geoffrey T.Huntington, A Unified Framework For The Numerical Solution Of Optimal Control Problems Using Pseudospectral Methods, Automatica, Vol. 46, Issue 11 (2010), pp. 1843- 1851