Parallel Computing
The Parallel Computing capability enables Ansys Systems Tool Kit® (STK®) application to distribute many of its most computationally complex analysis tasks across multiple computing cores on the computer where it is installed.
Parallel Computing also includes software development kits (SDKs) for .NET, Java, and Python. These SDKs make it easy to parallelize the execution of custom models and algorithms.
You can use the Parallel Computing capability either with multiple cores on a single standalone machine or with multiple machines interconnected in a cluster.
Licensing
You will need an Ansys HPC license and one of the following licenses:
| Capability | Pro license | Premium (Air/Space) and Enterprise |
|---|---|---|
| Parallel (local) | 8 cores | 16 cores |
| Parallel (cluster) | Uses the HPC license to determine the number of cores used. | |
You can only use one STK application license at a time, either local or cluster.
Computing with multiple machines in a cluster requires a Parallel Computing server. For more information, see the separate
The following paragraphs detail each configuration.
Standalone computer
In the case of a standalone computer, Parallel Computing will utilize the cores available on the local machine to perform the computation. The extension is installed automatically with the regular STK_ODTK install.
While it is not strictly required to understand how everything works in order to use the parallel capabilities, here are a few highlights that might facilitate troubleshooting. Basically, as shown in Figure 1, Parallel Computing exports the current scenario to a temporary VDF and then spawns worker processes to parallelize the computations. By default, it uses one worker per core. Each worker performs a part of the computation, and then the results are sent back to the STK desktop application through shared memory. Then the STK desktop application combines the results together.
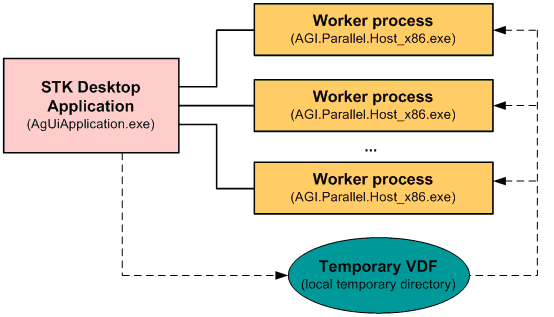
Figure 1: Standalone machine configuration.
The advantage of this configuration is that it is straightforward to set up, as everything is local to one machine. It is also included with the STK application and works right out of the box with a standard STK installation. However, this configuration only enables you to scale vertically, meaning that to improve performance you need to add more resources, such as CPU and RAM, to your local machine. In the case of big STK coverage, deck access, chain access, or volumetric computations, it might also be advantageous to scale horizontally (i.e., add more machines to share the work), which you can achieve by using a cluster of machines.
Cluster of machines
In the cluster configuration, there are several machines involved with different roles:
- Clients running the STK desktop application submit tasks to a centralized coordinator.
- The coordinator receives the work requests from the client(s) and distributes the tasks to agents.
- The agents execute the tasks. Only one agent runs per machine in the cluster. By default, the number of hosts running in parallel on a machine is set to the number of logical cores available on that machine. However, you can overwrite this default setting when configuring the agents.
- The coordinator and the agent tray applications provide a way to configure and monitor the activity of the coordinator and of the agent(s). The coordinator and the agents run as Windows services.
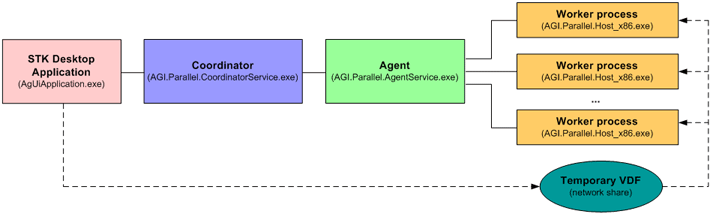
Figure 2: Cluster configuration
Figure 2 shows how the clients, coordinator, and agents interact. These three programs could be running on the same machine, or they could also be running on three separate machines. The agents spawn worker processes that run on the same machine as the agent itself.
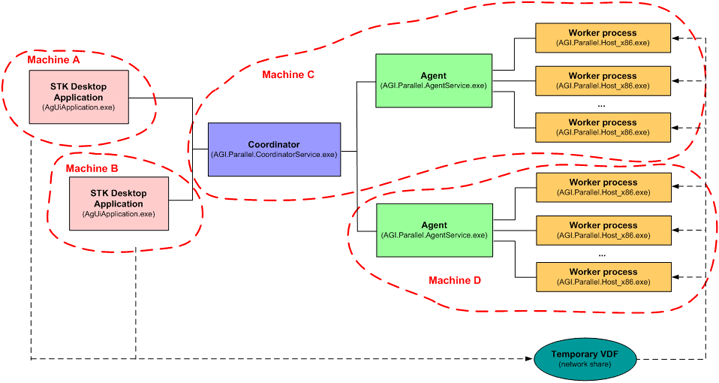
Figure 3: Example of a cluster
Figure 3 shows an example where two clients running the STK application use a two-machine cluster to perform computations: the first machine running both the coordinator and the agent, and the second machine running only the agent. You can scale horizontally in this configuration simply by adding more machines to the cluster.
For more details about managing the cluster, see the separate