Darwin Algorithm
Description
Darwin is a genetic search algorithm developed specifically for solving engineering optimization problems. Darwin is capable of handling discrete variables, continuous variables, and any number of constraints. Because Darwin does not require gradient information, it is able to effectively search non-linear and noisy design spaces.
More Information
Darwin is a genetic optimizer that can solve constrained design problems. It supports continuous and discrete variables. A penalty function is used to handle violated constraints. It uses elitist method to keep best design(s) from the previous generation. When more than one objectives are defined, Darwin will search for a series of best designs (Pareto set) using non-dominated design search.
Trade Study Resume
Darwin supports continuing a trade study after a halt or crash. All data up to the last generation will be restored, and the optimization will continue from there. See the general Optimization Tool documentation for more general information on resuming Trade Studies.
Control Parameters
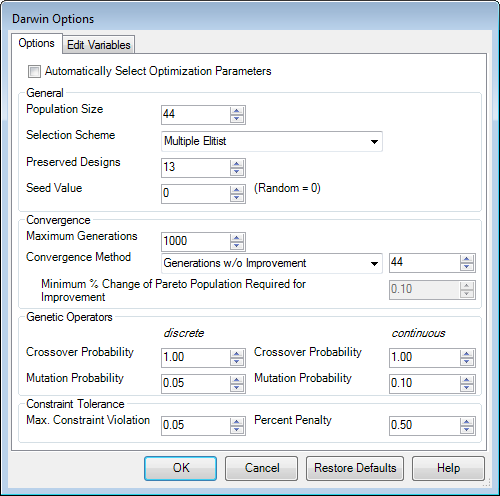
Population Size: The population size is the number of designs in each population. The size of the population is fixed throughout the optimization process, and should have a value that is greater than 1. In general, the larger the population size, the longer the optimization process will run because of the increased number of component runs required. Thus, the population size should be initially set as small as possible and then slowly increased if it appears that the optimizer is not converging consistently to the best design.
Selection Scheme: The genetic algorithm's selection scheme is the mechanism that determines which designs from the parent population and newly created child population will be chosen to make up the next generation of designs. The selection scheme ensures that the optimization procedure continually progresses towards an optimal solution by allowing the best design(s) in each generation survive in the next generation. Darwin utilizes two different types of selections schemes: Elitist selection and Multiple Elitist selection.
Elitist selection takes the worst design from the child population and replaces it with the best design from the parent population. The Elitist method provides more of an explorative genetic search since each successive population is provided with a large number of new designs. Therefore, Elitist selection is generally effective for optimization problems with a single optimum point that is not surrounded by a large number of local optima. The potential problem with Elitist selection is that important genetic information that may exist in other desirable designs of the parent population is lost. Thus, it is probable that Elitist selection will be incapable of finding multiple global optimum points in the search space.
Multiple Elitist selection is more effective for problems where the search space has multiple global optimum points, or for problems where the global optimum is surrounded by many local optimum points. In Multiple Elitist selection, the parent and child populations are combined into one population and ranked. Members of the combined population are then arranged from best to worst according to their fitness values. The Number of Preserved Designs, Np, specifies the number of best designs from the combined population that will be passed on to the next generation, and is used to control the selection pressure of the genetic algorithm.
If Np is equal to the population size (the maximum possible value of Np), then the next generation is filled with the first half of the combined population and the procedure is complete. If Np is less than population size, then the top Np designs from the combined population comprise the first part of the new generation. To fill the remainder of the new generation the ranked child population is searched, starting from the best design, for designs that have not already been passed on to the new generation. The first child found which is not located in the new generation is placed in first empty location in the new generation, and successive children fill out the rest of the new generation. Although the multiple elitist method may appear identical to the elitist method when Np = 1, this is not necessarily the case. When the top design comes from the child population the next generation will consist entirely of child designs. However, if the top design comes from the parent population, then the Elitist and Multiple Elitist selection methods are identical.
As the value of Np increases, the number of new designs entering the population decreases, causing the genetic search to become more localized. Thus, using large values of Np will prevent Darwin from exploring the design and may cause it to get trapped in a local optimum area of the search space. Therefore, the value of Np should be kept relatively small (less than 50%) compared to the population size so that a number of good designs can be tracked while maintaining a sufficient influx of new designs to continue searching other areas of the design space effectively.
Seed Value: The genetic algorithm's initial population is generated randomly, and its genetic operators are implemented with user specified probabilities. Thus, the outcome of a given optimization run is not deterministic - successive optimization runs may potentially yield different results (or the path that the optimizer takes to get the same result may be different). In general, this is the desired behavior, but there may be circumstances where the user may wish to duplicate the results of a previous optimization run (to output additional data, for example).
The Seed Value field allows the user to specify a seed for use by the optimizer's random number generator. If the optimizer is run successively with the same seed, identical results will be generated each time (assuming no other parameters have changed). If the seed value is set to zero (the default), the optimizer will generate its own seed, which will (in general) be different each time the optimizer is run.
Convergence: There are two convergence methods that may be used to terminate the optimization process. The first method is to fix the number of generations that the optimizer will execute. This is done by selecting Fixed Generations from the convergence method drop down box. The number of generations that the optimizer will execute is then specified in the Maximum Generations field.
The second convergence method instructs the optimizer to continue until a user specified number of generations has been run without any improvement in the best design(s). This convergence method is specified by selecting Generations w/o Improvement from the convergence method drop down box and specifying the maximum number of generations without improvement in the field to the right of this drop down box.
The concept of improvement is different for single objective and multi-objective optimization problems. For single-objective optimization, improvement is measured by the fitness of the best design. In this case, a counter is incremented by one if the top design in the current generations isn't better than the top design in the previous generation. If the counter reaches the value specified in the text field next to convergence method drop down box, the optimization procedure is terminated. The counter is reset to zero if the top design in the current generation is the best design found so far by Darwin.
For multi-objective optimization problems, there is no one design that is considered 'best' in each generation. Therefore, a different definition for improvement across successive generations is used to determine when Darwin has converged. For Darwin to achieve improvement, the percentage of Pareto-optimal designs that have changed from one generation to the next must be above a certain value. This value is specified in the Minimum % Change of Pareto Population Required for Improvement text field. For example, if the Minimum % Change of Pareto Population Required for Improvement is set 0.1, 10% or less of the pareto-optimal designs must change across successive generations to increment the generations without improvement counter. If Minimum % Change of Pareto Population Required for Improvement is set to 0, the set of Pareto-optimal designs across successive generations must remain the same to increment the generations without improvement counter. Note that the Minimum % Change of Pareto Population Required for Improvement text field will only be enabled if more than one objective has been specified.
When using the generations without improvement convergence criterion, the total number of generations that the optimizer will run is unknown, but will never exceed the number specified in the Maximum Generations text field.
Genetic Operators: The optimization algorithm implements each genetic operator with its own specific probability, P. To determine whether or not a specific operator will be implemented, a uniformly distributed random number is created and compared against the operator's probability. If the random number is smaller than P, the operator is applied to the genetic string(s).
The Crossover operator is typically applied with a high probability (0.8 = Pc = 1.0) because they are the genetic algorithm's primary means of traversing the search space. If crossover is not applied, then the parent strings are cloned into the child strings. Child strings are forced to be distinct from each other and from other designs in the parent population. If a distinct child cannot be found after a prescribed number of iterations, then one of the parents is cloned into the child population. The crossover process is repeated as many times as necessary to create a new population of designs.
Mutation performs the valuable task of preventing the premature loss of important genetic information by occasionally introducing random alterations in the genetic strings. Mutation is also needed because there is a low probability that the value at one or more locations in a design's genetic string will be identical to all other designs in the population as some point during an optimization run. Mutation is almost always applied with a low probability (0.01 = Pm = 0.3) and is implemented by changing, at random, a single value in the string to any other permissible value.
Constraint Tolerance: In a genetic algorithm, designs are ranked (best to worst) according to their fitness. The fitness of a given design is generally expressed as:
fitness = objective + penaltywhere objective is the value of the objective function, and a penalty is added to (or subtracted from) the objective function. If all of the design constraints are satisfied, the penalty term is zero. If one or more of the constraints is violated, the penalty is non-zero, and its magnitude is generally proportional to the magnitude of the constraint violation. It follows the basic function:
penalty = percent_penalty*(total_constraint_violation/max_constraint_violation)^2.5
The constraint tolerance options (Max Constraint Violation and Percent Penalty) allow the user to exercise limited control over how the penalty term is applied. Percent Penalty, specifies the percentage (e.g., 0.5 = 50%) by which the objective function will be penalized when the total constraint violation equals Maximum Constraint Violation. The penalty will be small for total constraint violations less than Maximum Constraint Violation, but will grow rapidly as the constraint violation exceeds Maximum Constraint Violation.
If the optimizer is rejecting designs that you think are acceptable, then Maximum Constraint Violation should be increased and/or Percent Penalty should be decreased. Likewise, if the optimizer is retaining designs that you think should be rejected, then Maximum Constraint Violation should be reduced and/or Percent Penalty should be increased.
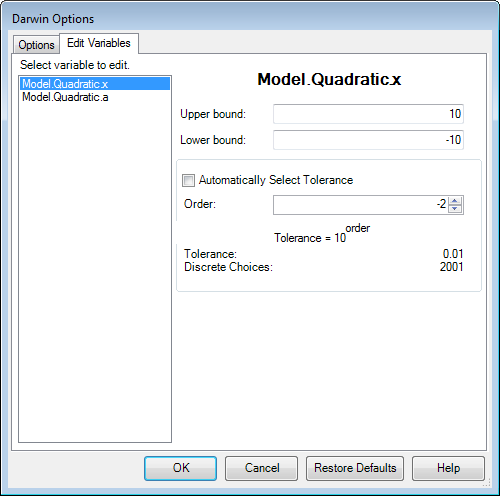
Tolerance Editing
By default, Darwin will automatically choose a "tolerance" for each continuous variable. This tolerance will control the number of decimal places that the optimizer will consider for this variable. For example, if the tolerance is set to a value of 0.01, Darwin will not consider differences less than 0.01 for this variable. Darwin will still consider the variable as a continuous variable for the purposes of crossover and mutation, but will round the variable to the nearest 0.01 before running each simulation.
The automatically selected tolerance will depend on the variable's upper and lower bounds. If the range between the upper and lower bounds is large, the tolerance will be selected to be relatively large. Likewise, if the variable range is small, the automatically selected tolerance will be relatively small. The optimizer will generally try to select the tolerance so that there will be a maximum of 10000 "discrete choices" between the variable's upper and lower bounds.
The automatically selected tolerance can be modified by the user at any time. To do this, open the Darwin options dialog by pressing the Options button in the Optimization Tool when Darwin is the selected algorithm. Select the Edit Variables tab, and select the name of the variable whose tolerance you would like to modify. Uncheck the "Automatically Select Tolerance" checkbox, and then change the tolerance by entering a value in the "Order" text field . The tolerance will be set to a value equal to 10order.
By judicious selection of continuous design variable tolerances, the user can control the size of the design space and thereby influence the convergence characteristics of the algorithm. Reducing the tolerance for a variable will increase the size of the design space, and increasing the tolerance will decrease the size of the design space.