Basic Definitions [1]
In reliability analysis failure is generally represented using limit states. A response variable or a response function or a Z-function is a function like stress, strain, displacement, fatigue life, etc. or any function computed with a bunch of input values. The response variable can be a simple close formed equation or could be something computed using CAE or CFD or any other form of analyses. This function is the one in which we are interested while studying reliability of a design.
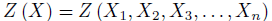
where Xi (i = 1,2,..,n) are design variables or so called input random variables.
A g-function is a limit state function and is also sometimes referred to as performance function.
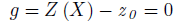
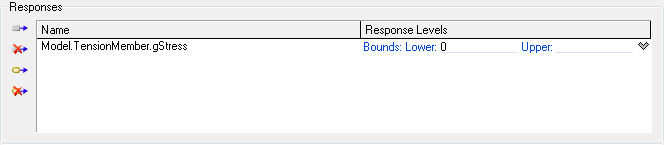
where z0 is a particular value of Z. This value is generally the limit value of the Z-function under consideration. The g-function is defined such that g(X) = 0 is a boundary that divides the random variable space into two regions: failure (g<= 0) and safe (g>0). Thus if we had a case where there was an upper limit of 200 MPa on stress. The g-function would be gStress = 200 - Stress(X) = 0. Thus if the Stress were to be beyond 200 it would be a failure for the design and the gStress clearly represents that. In Analyzer, the response function gStress may be computed using a Script component where the previous equation is computed. Model.TensionMember.gStress is dragged into Probabilistic Analysis Tool and the Lower Bound is set to 0 which would mean we want Pr (gStress <= 0), thus anything greater than the Lower Bound will represent safe region. Thus the tool would then compute the probability of failure. Using g-function is a good practice as it would be easy to identify failure region. In case gStress was not used, the probability of failure can be determined by setting 200 as the Upper bound for response variable stress in the Probabilistic Analysis Tool.
Given a g-function and joint probability density function, the probability of failure is the probability in the failure domain 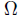 and is given by:
and is given by:
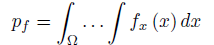
This can be computed using standard Monte Carlo. However, when g-function is complicated and computing it is time consuming for each sample of X, and pf is small, this random sampling technique becomes impractical. Thus efficient methods have to be used.
References:1. NESSUS Theoretical Manual, February 17, 2012, Section 2.1