The following sample diagrams depict the flow of data in various RT3-based solutions.
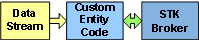
Raw Data —> Entities —> STK Broker
In this example, the entity library and the STK broker plugin are used to display data directly from a raw data stream. The “Custom Entity Code” block is converting the raw data stream into entity objects directly, without writing an entity provider plugin. It is then setting all the parameters, graphical and otherwise, for each entity itself and putting the entities directly into the STK broker. It is a good workflow to use if you have a very small number of tracks - especially if they have a high update rate; it cuts out much of the processing overhead you would want in order to process large volumes of data, with the benefit of delivering better performance. The down side of this workflow is that you need to micro-manage each entity yourself, which means that it is not an optimal solution for large data sets; it is best for one-off solutions where flexibility and reusability are not needed.
Entity Providers —> RT3 —> STK Broker
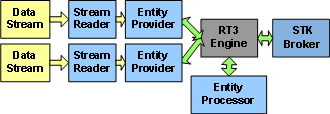
Two entity provider and stream plugins are fed directly into the RT3 engine in the example above. An entity processor is then used on every entity, possibly for correlation or some other task. Entities matching query and event criteria (not shown) are then pushed into the STK broker for use in STK or AGI Viewer. This is the most common workflow of RT3; a large amount of data is fed into the client from multiple sources and processed, sorted and graphically tagged data is then output to the display.
STK Programming Interface 11.0.1