Deletion in Bounding Volume Hierarchies |
While under development, the Insight3D development team wrote a series of blog posts, which are now archived here to provide in-depth technical information about some of the underlying techniques and design decisions. These posts reflect the work-in-progress state of the product at the time.
The following blog post was originally published on the Insight3D blog on February 13, 2008 by Patrick Cozzi. At the time of publishing, Insight3D was referred to by its development code-name, "Point Break".
Bounding volume hierarchies (BVHs) were popularized in the ray tracing community by Goldsmith and Salmon in their 1987 paper Automatic Creation of Object Hierarchies for Ray Tracing. In 1988, Eric Haines followed with an article in the Ray Tracing News providing an excellent explanation of creating near optimal bounding volume hierarchies given a list of objects, based on Goldsmith and Salmon's paper.
Two decades later, there is still significant interest in BVHs. In 2006, Lauterbach et al. published RT-DEFORM: Interactive Ray Tracing of Dynamic Scenes using BVHs and in 2007, Eisemann et al. published Automatic Creation of Object Hierarchies for Ray Tracing of Dynamic Scenes. Both of these papers describe using BVHs to reduce the number of intersections calculated per ray for ray tracing dynamic scenes, i.e. scenes with moving objects.
Point Break doesn't care much about ray tracing but it cares a lot about efficiently rendering dynamic scenes which led me to these ray tracing papers. Besides being useful for ray tracing, BVHs are useful for hierarchical view frustum culling. The intersection algorithm is basically the same; just replace the ray/sphere test with a frustum/sphere test. Primitives use BVHs for this purpose.
Although there is a lot of literature on inserting objects into a BVH and updating objects in a BVH, there isn't much in the way of deleting objects from a BVH. This may be because some approaches to the problem are straightforward or because many application don't need to delete objects from BVHs; they just delete the whole BVH. Point Break needs to delete objects from BVHs. In some cases, deletion from a BVH is done in response to a GUI action such as hiding latitude/longitude lines or turning off the ground track or a model representing a satellite.
I will present a method to delete objects from a BVH that takes advantage of the objects' spatial locality and typically does not require an O(n) tree traversal to cleanup afterwards. Deletion is expected log(n). With good spatial locality, many deletions will be constant time. Deletions are batched and cleaned in a pass with a run-time proportional to the number of dirty nodes. Although the tree is cleaned up (bounding volumes are recomputed, interior nodes are deleted or merged), it is still susceptible to becoming less optimal over time. Both Lauterbach and Eisemann present criterion to determine when a BVH, or one of its sub-trees, has degraded to the point that it should be rebuilt.
Similar to Eric Haines' article, interior nodes contain pointers to their children and only leaf nodes contain pointers to objects. In addition, each node contains a pointer to its parent as well as a boolean value indicating if it is dirty. As you will see, leaf nodes do not need to maintain this dirty flag. Objects also contain pointers back to their leaf node. As Eisemann mentions, a big advantage of BVHs is every object is contained in just one leaf node, which makes a back pointer like this possible. Maintaining these extra pointers only adds slight bookkeeping to the insertion algorithm.
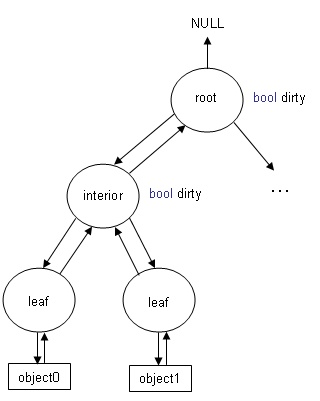
A trivial deletion algorithm is given an object, retrieve its leaf node, delete the leaf node and remove the leaf node from its parent. This can quickly lead to a tree with unnecessarily large bounding volumes and interior nodes with no children. One possible solution is, after removing the leaf node, walk up the parent node pointers, recomputing the node's bounding volumes and deleting nodes with no children. This increases deletion from constant time to expected log(n) time and deleting objects near each other would cause parent bounding volumes to recompute multiple times. To remedy this and achieve constant time deletion, instead of walking up parent pointers, just mark the parent as dirty. After a batch of objects is deleted, the tree can be cleaned with an O(n) traversal. If only a single object is removed, this slows deletion down to O(n); but if many objects are deleted, the O(n) traversal is amortized over the cost of each deletion.
Given these solutions, it's easy to construct an algorithm that takes advantage of the spatial locality of deleted objects to achieve good performance. As usual, deletion is done in two phases.
Given an object to delete, delete its leaf node and remove the leaf node from the leaf's parent. If the leaf node's bounding volume was flush against its parent's bounding volume or the parent now has less than two children, mark the parent as dirty. Continue walking up parent pointers, marking them dirty, until you find a node that is already dirty or is the root node (which should be marked dirty as well).
Once per frame, hopefully after several objects near each other were deleted, clean the tree. Start at the root and only follow children that are marked as dirty. Once the recursion starts unfolding, recompute the nodes' bounding volumes bottom-up, delete nodes with no children, and merge nodes with only one child.
The deletion operation is expected log(n) but if an object is deleted that is in a sub-tree with an object that was already deleted, the parent pointers are not walked all the way to the root, allowing these types of deletions to run in near constant time. Cleaning the tree is still O(n) if a wide range of objects were deleted. If all the objects deleted were in the same area, cleaning will be closer to log(n).
This algorithm is best illustrated with an example. Suppose we create a BVH of spheres with 5 objects that have centers along the x axis. This is shown in the following code and image.
object0->node = bvh.Insert(Sphere(Vector( 0, 0, 0), 2), object0); object1->node = bvh.Insert(Sphere(Vector( 4, 0, 0), 1), object1); object2->node = bvh.Insert(Sphere(Vector(-3, 0, 0), 1), object2); object3->node = bvh.Insert(Sphere(Vector(-1, 0, 0), 1), object3); object4->node = bvh.Insert(Sphere(Vector( 1, 0, 0), 1), object4);
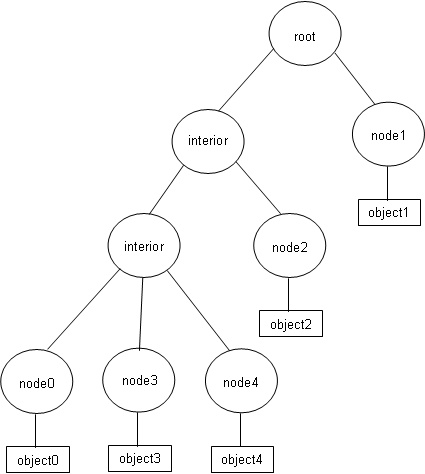
Parent pointers and arrows are not shown for clarity. Now suppose the three deepest objects, whose leaf nodes all share the same parent, are deleted from the tree and then the tree is cleaned.
bvh.Delete(object0->node); bvh.Delete(object3->node); bvh.Delete(object4->node); bvh.Clean();
After the first delete, object0->node is removed from the tree and its parents up to the root are marked as dirty as shown below.
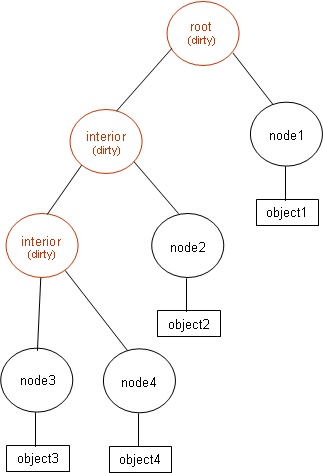
Deletion of object3->node and object4->node do not require walking parent pointers since they were marked dirty by the first deletion. After the three deletions but before the cleaning, the tree looks like:
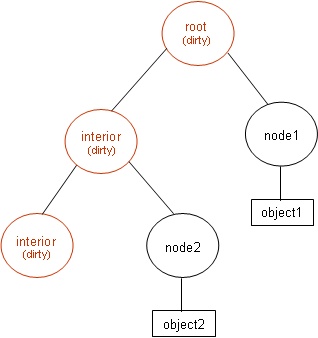
When cleaning occurs, the roots right sub-tree is not touched since it is not dirty. This is both the algorithm's strength and its weakness since maintaining an optimal tree may involve manipulation of nodes in both sub-trees. After cleaning, the dirty nodes' bounding volumes are recomputed and the unnecessary interior nodes are deleted.
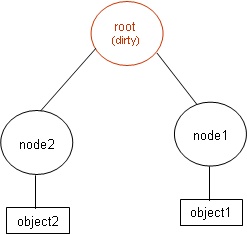
If you've implemented insertion into a BVH, this deletion algorithm will be easy to implement. I've left a few details to your imagination. Can (or should) you allow interleaving of insertions and deletions? Do you want to rely on a heuristic tree search for insertion when there are dirty nodes in the tree? Keep in mind that for tree cleaning to work, the following invariant must hold true: if a node is dirty all its parents up to the root are also dirty.
The best case for deletion is the first delete takes log(n) and additional deletes are constant time. Then, updating the dirty nodes is log(n). The worst case for deletion is log(n) for each deletion (although once all nodes are marked dirty, deletion will be constant time) and O(n) for updating the dirty nodes. In practice, I don't expect either extreme is common but given the spatial locality of many deletions, I would expect the run-time being closer to the best case.